


PrometheusRule 与 Blackbox Exporter 集成告警配置指南
在现代云原生监控体系中,仅仅知道服务是否可用是不够的,更重要的是在服务出现问题时能够及时收到通知并快速响应。PrometheusRule 是 kube-prometheus-stack 中用于定义告警规则和记录规则的自定义资源,通过与 Blackbox Exporter 结合,我们可以实现对网络服务可用性的实时监控和自动告警。
一、技术背景
Blackbox Exporter 是 Prometheus 生态系统中的重要组件,专门用于黑盒监控,即从外部探测目标服务的可用性。它支持多种探测协议,包括 HTTP、HTTPS、TCP 等,可以监控任何可以通过网络访问的目标。
然而,Blackbox Exporter 本身只负责收集和暴露探测指标,不会主动发送告警通知。为了实现自动告警功能,我们需要结合 PrometheusRule 来定义告警规则,并通过 Alertmanager 进行告警通知的处理和分发。
通过Notification Manager,PrometheusRule 可以与外部平台(如钉钉、企业微信、邮件等)进行集成,实现对告警的实时通知。
1.1 核心组件
| 组件 | 作用 |
|---|---|
| Blackbox Exporter | 执行探测任务并收集指标 |
| Probe | 定义探测目标和策略 |
| PrometheusRule | 定义告警规则和记录规则 |
| Prometheus | 评估告警规则并发送告警 |
| Alertmanager | 处理告警通知 |
1.2 工作原理
+----------------+ +------------------+ +------------------+
| Probe资源 | | Blackbox Exporter | | Prometheus |
| 定义探测目标 |------>| 执行探测任务 |------>| 收集指标数据 |
+----------------+ +------------------+ | |
| |
| +-------------+ |
| |PrometheusRule| |
| |定义告警规则 | |
| +-------------+ |
+------------------+
|
v
+------------------+
| Alertmanager |
| 发送告警通知 |
+------------------+
|
v
+------------------+
| Notification |
| Manager |
| 发送到具体平台 |
| (钉钉、企业微信、邮件等)|
+------------------+
二、关键监控指标
Blackbox Exporter 提供了丰富的监控指标,其中最重要的几个指标用于判断服务的可用性:
2.1 核心指标说明
| 指标名称 | 类型 | 说明 | 告警用途 |
|---|---|---|---|
probe_success | Gauge | 探测是否成功 (1=成功, 0=失败) | 判断服务是否存活 |
probe_duration_seconds | Gauge | 探测持续时间(秒) | 判断服务响应速度 |
probe_http_status_code | Gauge | HTTP状态码 | 判断HTTP响应状态 |
probe_ssl_earliest_cert_expiry | Gauge | 最早过期证书时间戳 | 判断SSL证书有效期 |
三、PrometheusRule 配置详解
PrometheusRule 是 Prometheus Operator 提供的自定义资源,用于定义告警规则和记录规则。通过定义合适的告警规则,我们可以在服务出现问题时及时收到通知。
3.1 基本结构
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: blackbox-exporter-rules
namespace: monitoring
labels:
app: blackbox-exporter
spec:
groups:
- name: blackbox-exporter.rules
rules:
# 告警规则定义
3.2 核心字段说明
| 字段 | 说明 | 可选值 | 默认值 |
|---|---|---|---|
apiVersion | API版本 | monitoring.coreos.com/v1 | - |
kind | 资源类型 | PrometheusRule | - |
metadata.name | 规则名称 | 任意合法名称 | - |
metadata.namespace | 命名空间 | 有效的命名空间名称 | - |
metadata.labels | 标签 | 键值对 | - |
spec.groups | 规则组 | 规则组数组 | - |
spec.groups[].name | 规则组名称 | 任意合法名称 | - |
spec.groups[].rules | 规则列表 | 规则数组 | - |
四、告警规则配置实践
根据实际使用的配置文件,我们的告警规则如下:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: blackbox-exporter-rules
spec:
groups:
- name: blackbox-exporter.rules
rules:
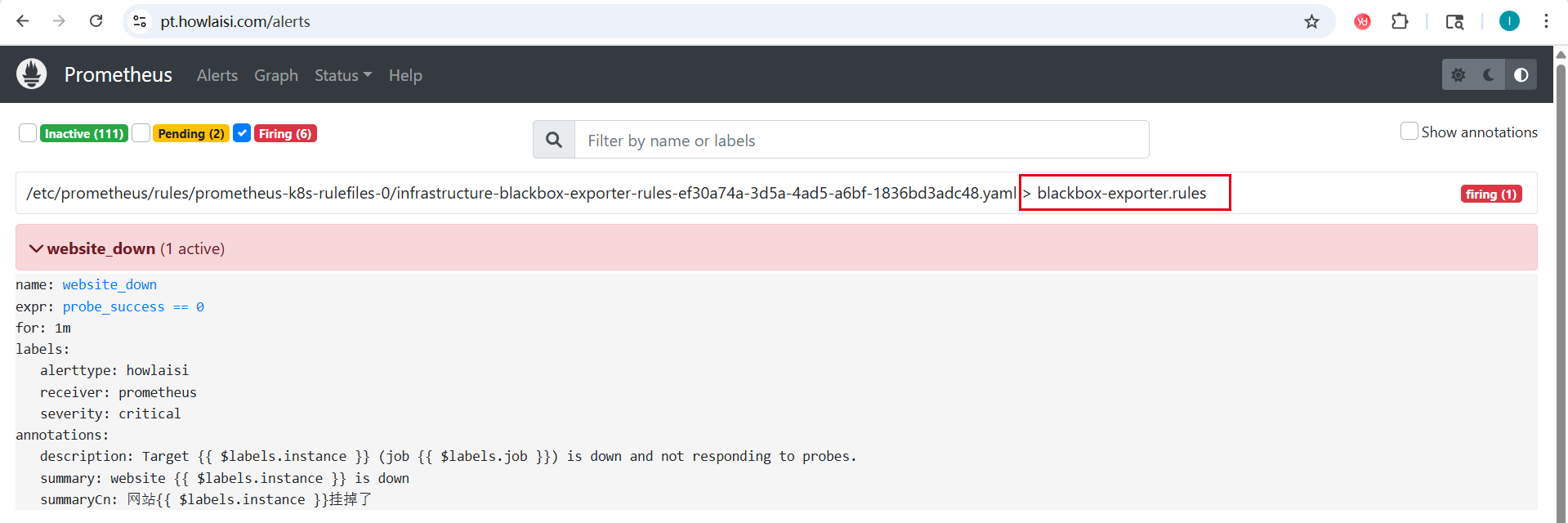
- alert: website_down
expr: probe_success == 0
for: 1m
labels:
severity: critical # 告警级别
receiver: prometheus # 定义告警接收者
alerttype: howlaisi # 这个要和alertmanager联动。
annotations:
summaryCn: "网站{{ $labels.instance }}挂掉了"
summary: "website {{ $labels.instance }} is down"
description: "Target {{ $labels.instance }} (job {{ $labels.job }}) is down and not responding to probes."
4.1 告警规则字段详解
| 字段 | 说明 | 示例值 |
|---|---|---|
alert | 告警名称 | website_down |
expr | 告警表达式 | probe_success == 0 |
for | 持续时间阈值 | 1m |
labels | 告警标签 | severity: critical |
annotations | 告警注解 | summary: "website is down" |
4.2 标签说明
在我们的实际配置中,使用了以下标签:
| 标签 | 说明 | 值 |
|---|---|---|
severity | 告警严重程度 | critical |
receiver | 告警接收者 | prometheus |
alerttype | 告警类型 | howlaisi |
这些标签将与 Alertmanager 的路由规则配合使用,确保告警能正确发送到指定的接收者。
4.3 注解说明
配置中包含以下注解:
| 注解 | 说明 | 内容 |
|---|---|---|
summaryCn | 中文摘要 | 网站{{ $labels.instance }}挂掉了 |
summary | 英文摘要 | website {{ $labels.instance }} is down |
description | 详细描述 | Target {{ labels.instance }} (job {{ labels.job }}) is down and not responding to probes. |
五、部署与验证
5.1 部署规则
将上述配置保存为up-rule.yaml 文件,同时确保 kustomization.yaml 包含该规则文件,然后使用 argocd 部署
resources:
- up-rule.yaml
5.2 验证规则
部署后,可以通过以下方式验证规则是否生效:
- 检查规则是否被正确加载:
# 根据实际部署情况修改命名空间参数
kubectl get prometheusrules -n <实际部署的命名空间>
- 在 Prometheus UI 中查看规则:
- 访问 Prometheus Web UI
- 导航到 "Alerts" 页面
- 确认告警规则已显示在列表中
- 模拟故障验证告警:
- 暂时关闭某个被监控的服务
- 等待告警触发时间(根据 for 参数)
- 检查 Alertmanager 是否收到告警
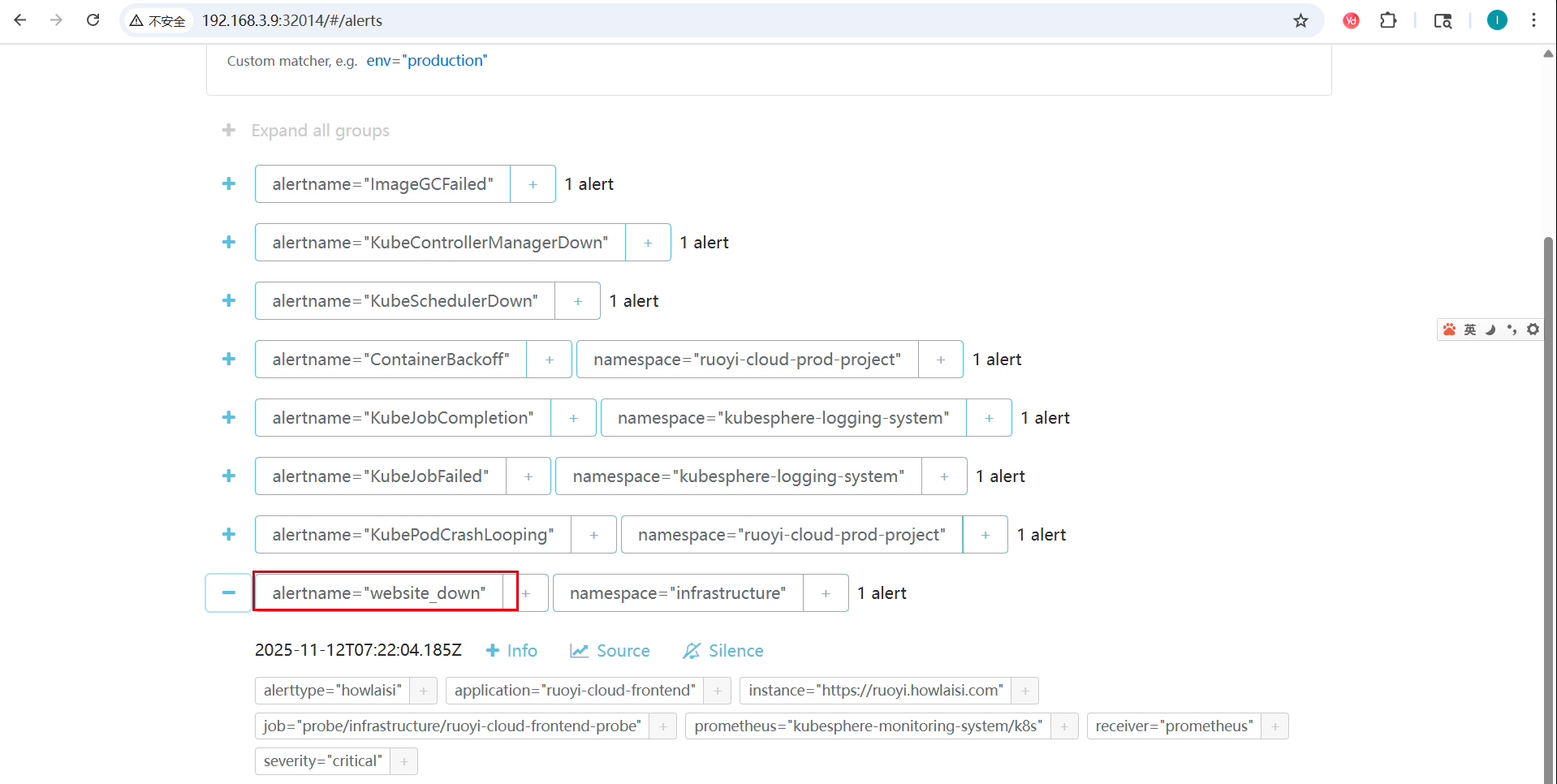
六、Alertmanager 配置联动
为了确保告警能正确发送,Alertmanager 需要配置相应的路由规则来处理带有 alerttype: howlaisi 标签的告警,.*代表匹配所有字符串,由于当前有kubesphere自带的规则,后续可以按照格式匹配alerttype: howlaisi,只发自定义的告警。
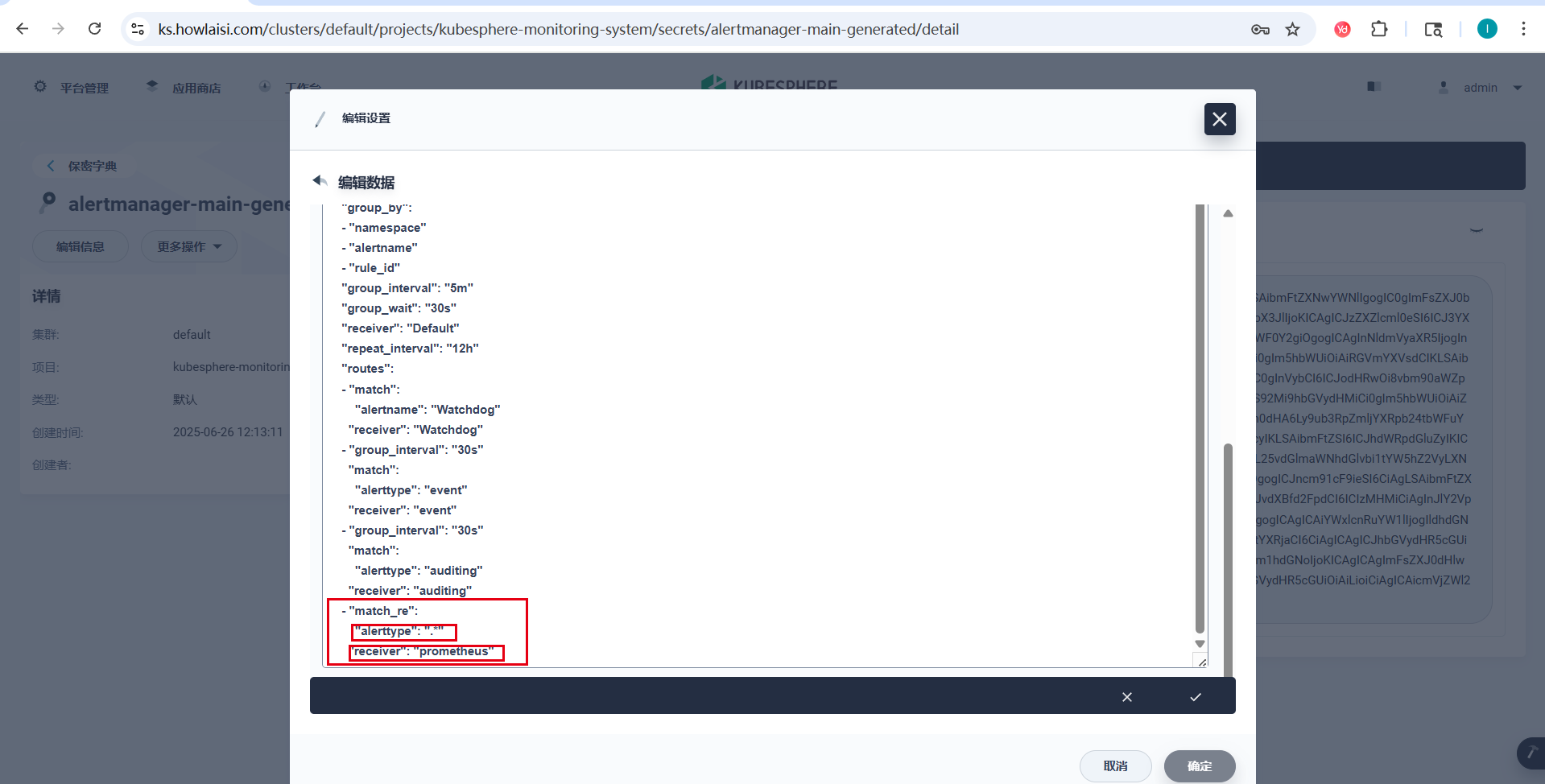
6.1 路由配置示例
route:
group_by:
- namespace
- alertname
- rule_id
group_interval: 5m
group_wait: 30s
receiver: Default
repeat_interval: 12h
routes:
# ... 其他路由规则
- match_re:
alerttype: .*
receiver: prometheus
这样,所有带有 alerttype 标签的告警都会被发送到 prometheus 接收器,然后通过 webhook 转发给 Notification Manager 进行处理。
七、告警调优建议
7.1 合理设置告警阈值
- 告警触发时间:根据服务的重要性和SLA要求设置合适的 for 时间,避免因短暂网络波动导致误报
- 响应时间阈值:根据业务特点设置合理的响应时间阈值
- 证书过期时间:提前7-30天告警,确保有足够时间更换证书
7.2 告警分组与标签
- severity标签:使用 critical、warning 等标签区分告警严重程度
- 服务标签:为不同服务添加特定标签,便于告警分类和路由
- 环境标签:区分生产、测试等不同环境的告警
7.3 告警抑制
在某些情况下,可能需要设置告警抑制规则,例如:
- 当服务完全不可达时,抑制响应时间过长的告警
- 当SSL证书即将过期时,抑制服务不可达的告警(因为可能是证书问题导致)
八、常见问题与解决方案
8.1 告警规则未生效
问题现象:部署了PrometheusRule,但在Prometheus UI中看不到规则
根本原因:
Prometheus Operator 不会自动采集所有命名空间中的 PrometheusRule 资源。只有当 Prometheus 实例的配置明确指定要监控包含 PrometheusRule 的命名空间时,这些规则才会被加载和执行。
换句话说,虽然通过以下类似以下命令成功创建了 PrometheusRule(张师傅用的argocd):
kubectl apply -f up-rule.yaml
但如果 Prometheus 的 CRD(Prometheus 资源)没有配置去监控这个 PrometheusRule 所在的命名空间,Prometheus 根本不会加载这些规则。
逐步排查与修正:
-
检查 Prometheus 实例是否配置了 ruleNamespaceSelector
执行以下命令查看 Prometheus 配置:kubectl -n kubesphere-monitoring-system get prometheus k8s -o yaml在输出中找到类似以下的配置:
spec: ruleNamespaceSelector: {} ruleSelector: matchLabels: prometheus: k8s role: alert-rules该段表示会加载所有命名空间下的有
role: alert-rules以及prometheus: k8s标签的 PrometheusRule 对象。
解决方式:
修改 Prometheus CRD 配置以监控正确的命名空间和标签:
spec:
ruleNamespaceSelector: {}
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
如果需要监控所有命名空间中的规则,可以配置:
spec:
ruleNamespaceSelector: {}
ruleSelector: {}
8.2 告警频繁触发
问题现象:告警频繁触发和恢复,造成告警风暴
解决方案:
- 调整 for 参数,增加触发时间
- 优化探测间隔,避免过于频繁的探测
- 设置合理的告警抑制规则
8.3 告警通知未收到
问题现象:Prometheus显示告警已触发,但未收到通知
解决方案:
- 检查Alertmanager配置是否正确
- 确认告警路由规则是否匹配
- 检查通知渠道(如邮件、Slack等)配置是否正确
总结
通过 PrometheusRule 与 Blackbox Exporter 的集成,我们可以构建一个完整的网络服务监控和告警体系。合理的告警规则配置能够帮助我们及时发现服务问题,提高系统的可靠性和稳定性。
关键要点总结:
- PrometheusRule 是定义告警规则的核心资源
- probe_success 是判断服务存活的关键指标
- 合理设置告警阈值和触发时间,避免误报和漏报
- 结合 Alertmanager 实现多样化的告警通知
在实际应用中,建议根据具体业务需求和SLA要求,调整告警规则的参数和阈值,以达到最佳的监控效果。


评论区